输入法作为使用频率最高的软件之一,现有市场已经几乎被搜狗输入法垄断。也正是由于垄断,导致现有的输入法开发项目和开发资料比较少。在这里将自己最近收集的一些内容整理出来,供想做输入法开发的开发人员参考。
输入法开发最为重要的就是开发框架,它是输入法与系统中有输入焦点的应用之间连接的桥梁,将用户输入的文字传输到对应的应用中。
不同系统下输入法开发使用的框架不同
windows系统下使用的框架有:IMM-IME和TSF
Linux系统下使用的框架有fcitx和ibus
不同的框架应对的使用环境和使用场景不同。后面文章我会详细介绍。
不考虑使用频率较低的外文和少数民族文字,输入法输入针对的语言主要是英语和中文。而英文的输入模式较为单一,这里主要介绍的是中文的输入。
中文输入依据输入源可以分为:按键输入、语音输入和手写输入,语音输入和手写输入是最近几年随着AI技术发展而逐渐发展起来的输入方式。
语音输入和手写输入与AI算法关系比较紧密,这里也不做详细介绍。这里介绍一下常规的按键输入,按键输入模式按照输入原理不同可以分为字形输入和拼音输入,拼音输入又根据拆分模式不同分为全拼输入和双拼输入。
全拼输入就是按照正常的拼音输入然后获取候选词的方式,而双拼输入就是将每个字的音节拆分为声母和韵母,然后将声母和韵母与按键组合映射起来。这样就可以通过输入声母和韵母来输入对应的字了。比如风(feng)可以拆分成声母f和韵母eng,如果键盘上按键A映射f 按键B映射eng,通过AB按键组合输入就可以获得读音为feng的候选。
字形输入细化之后可以分为五笔输入、拆分输入、笔画输入,五笔输入可以用来输入字或者词而拆分输入和笔画输入主要用来输入比较生僻的字。由于五笔模式大家已经非常熟悉,这里只详细介绍一下拆分输入和笔画输入。在搜狗输入中笔画输入和拆分输入统称为u模式,通过按键u进行启动。
笔画输入模式中:
h键代表着笔画中的横
s键代表着笔画中的竖
p键代表着笔画中的撇
n键代表着笔画中的捺
z键代表着笔画中的折
比如要想输入木字按笔画可以拆分为横竖撇捺,对应按键hspn然后得到对应的候选结果。
拆分输入是将不常见的字或者读音比较生僻的字拆分成它的组成部分,然后通过它组成部分的读音获取这个字。比如想输入焱(yan),可以通过输入huohuohuo获得对应的候选。
为了方便大家的理解和记忆,对各种输入模式进行了整理,列表如下图所示: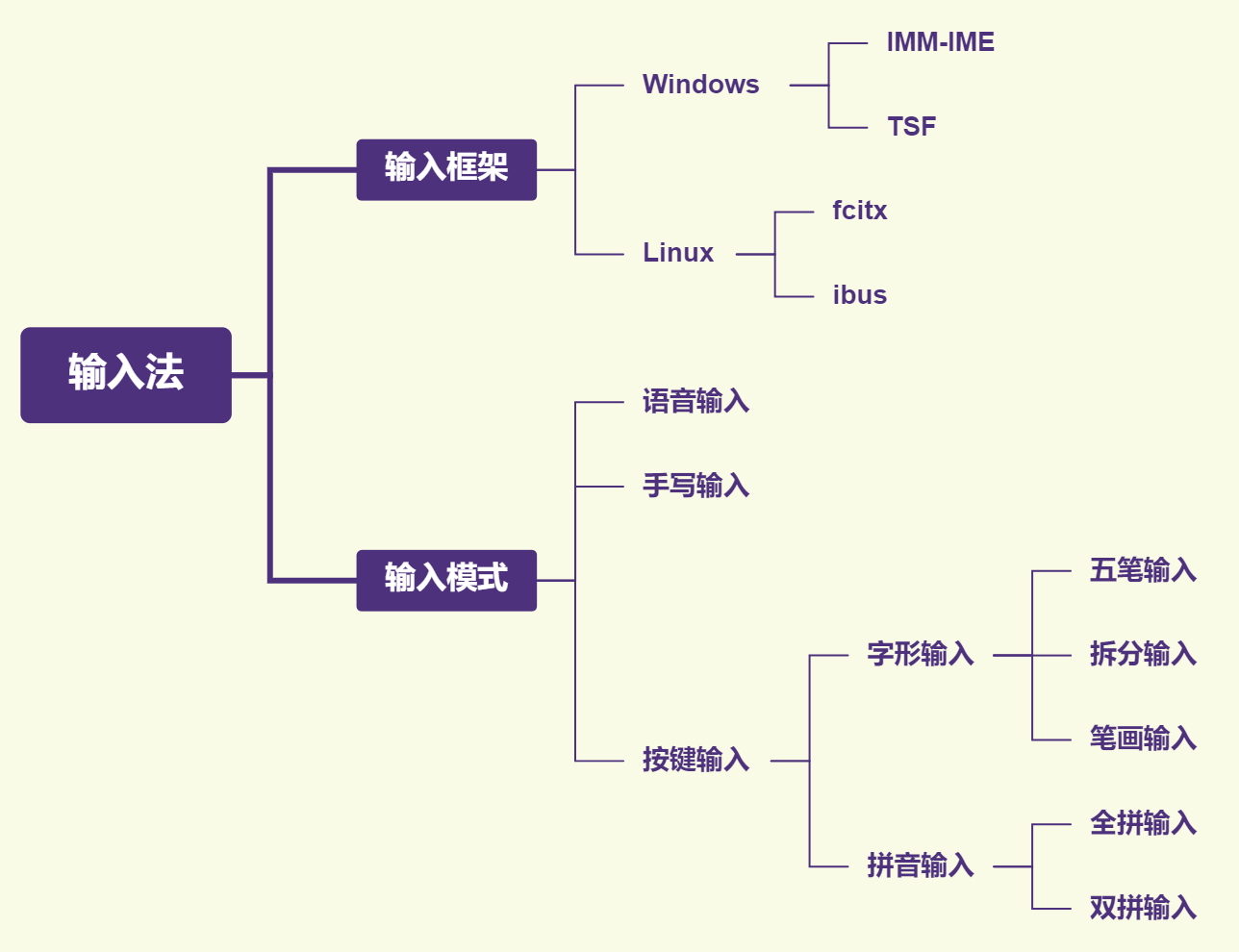
其实输入法使用频率最高的是在全拼输入模式下的词汇和语句的输入,下面对这方面的内容进行详细介绍。拼音模式下候选词,依据来源可以分为如下几种。
自定义短语(与用户定义相关)
词库短语(与词库相关)
智能组词短语(与组词模型相关)
词语联想短语(与词语联想模型相关)
为了提升全拼输入下的用户输入体验,很多输入法还添加了很多辅助功能,比如:模糊音功能、拼音纠错功能。
模糊音就是实现固定音节的模糊匹配,下面以搜狗的模糊音进行说明
我开启了z=zh的模糊音,这样在输入拼音z的时候会自动模糊匹配zh的候选
而智能纠错,就是将常见的错误拼音纠正成正确的拼音,比如我开启了gn ==>ng的智能纠错那么我输入hogn的时候会自动纠正为hong

依据使用体验来说呢,这两个功能,智能纠错建议全部开启,模糊音建议全部关闭因为会影响候选的精确性。
依据上面的介绍简单总结一下输入法获取候选的流程:
1.先根据系统配置获取输入原理是拼音输入还是五笔输入,如果是拼音输入还要确定是全拼输入还是双拼输入。
2.根据首字母确定输入子模式(是不是笔画输入或者拆分输入)
3.对输入的字符串进行音节解析,音节包括声母、韵母、以及音调,解析音节的时候要确定是否使用了模糊音和语音纠错。
4.根据输入的字符串和音节去检索候选词,候选词包括:
自定义短语、完整的词(从词库中去检索)、通过智能组词组出来的词、单个的字
简要的流程如下图所示: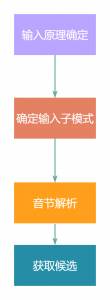
在这个过程中需要的资源包括:
1.字库资源(拆分字库,五笔字库,拼音字库,笔画字库)
2.词库资源(系统词库,专业词库,云词库,热词词库,英文词库,用户词库)
3.自定义短语(系统自定义短语,用户自定义短语)
4.特殊符号资源
用户资源中数据结构最复杂的就是词库资源,这里以最常见的词库数据结构进行介绍一下,词库其实就是一个二进制文件,具体的内容主要为音节和对应候选词的映射关系,结构内容主要包括:文件头、数据页两部分。
文件头中包含了词库的描述信息包括:
词库的名称
词库的作者
词库的词条数
词条的创建时期
词库的版本号
对应词库的索引表
词库的页数
其他的额外的描述字段。
数据页中主要存储了音节和对应的候选词,大家都知道词库的词条数量非常多。如何对候选词进行分类,才能让检索速度更快呢。这里提供一种方案。
由于词库的词条数据量比较大,需要依据音节对词库进行分页处理,每页中包含一部分词条。每个词条至少包含两个音节(两个字),依据前两个字的声母对词条进行分类,前两个字的声母相同的词条组成一页。而当前页中又存有下一页的编号,这样每种拼音组合的候选词就形成了一个链表,可以无限扩容。同时为了提高检索速度,每个词汇页的长度是固定的。
每一个候选页的内容包括:
1.当前页号
2.下一页的页号
3.本页中词汇长度标识 (包含哪些长度的词组)
4.已使用的数据长度
5.具体内容数据
具体内容数据中包含了每个词条信息:
1.词的有效性
2.词的长度
3.音节长度
4.词频
5.词的音节数组
6.词中每个字的Unicode值数组。
在词库中检索词的流程如下图所示:
1.先解析出输入的音节数组的前两个音节的声母
2.根据声母组合以及词库头中音节映射表找到对应音节组合的第一页页码
3.判断第一页中有没有满足对应音节长度的候选词,有的话进行查找,并加入候选词列表。没有的话查找下一页,依次循环直至查找到最后一页。
为了方便大家理解词库的数据结构下面画了一张简单的数据结构图
相关推荐
输入法开发之:疑难杂症套娃开始:当键盘事件被触发时,获得的参数是ITfContext。但是ITfContext并不能直接修改内容添加文字等,需要调用RequestEditSession,传入一个ITfEditSession
逗比的输入法实现(二):基础概念和常用接口为什么叫 Meow?因为这是给猫用的输入法。。。目录(一):基本情况(二):基础概念和常用接口(三):整体构架(四):编辑和候选(五):界面管理和无界面模式(六):词库和候选算法(七):皮肤的实现(八
[输入法]TSF框架中预先上屏的字符管理和控制在TSF框架中有时候我们需要通过框架上屏一些占位字符来进行定位,这时候我们就需要对预先上屏的字符进行管理,以微软的输入法为例图中红框框选出来的部分就是预先上屏的字符。在TSF框架中通过ITfRange
获取输入法坐标以下是微软TSF输入法取坐标的方法,从里面扒出来的int 取坐标(ITfContext *pContext, TfEditCookie ec, ITfComposition* pRangeCompos
微软输入法TSF SampleIME 源码分析(转载)类:CCandidateWindow,候选字窗口CCompositionPricessorEngine,拼写引擎CSampleIME,主程序CStringRange, 一个特殊的字符串类 见于 Sam
输入法的注册、安装和卸载注册输入法输入法的安装和普通应用程序有一个大的区别是,除了复制文件到安装目录、做一些必要的设置外,还需要向Windows系统注册这个输入法。我们前期一篇博文 TSF(Text Service Fram
Windows IMM-IME汉字输入法1.IMM与IMEIMM是Input Method Manage(输入法管理器)的缩写,IME是Input Method Editor(输入法编辑器)的缩写。微软公司在Windows 95/98/NT
TSF(Text Services Framework)和输入法1.TSF输入接口IMM-IME架构成熟,稳定,易于实现,在Windows中被广泛使用,甚至在Linux曾大量使用的中文输入接口SCIM中也可以看到IMM-IME的影子。但是由于IMM-IME在操作权
基于文本服务框架(TSF)的拼音输入法研究与实现摘要:目前的输入法大多采用输入法管理器-输入法编辑器(IMM-IME)进行开发,对于微软发布的新型输入法技术―文本服务框架(TSF)的研究一直比较滞后,该文论述了 TSF 的基本构成、主要接口、输入法
快速搭建一款输入法(封装输入法引擎)输入法最核心的是输入法引擎,输入法引擎负责加载和管理输入法配置和输入法的词库,输入法引擎对用户输入的拼音字符串进行处理并返回对应的候选列表。通过引入输入法引擎我们就可以将我们输入法的拼音串转换成对应的